
Redundancy enables upfront sampling instead of dimensionality reduction
Getting similar performance with 90% less resources - data, FLOPS, etc.

“Once a pattern is found in raw data, the data are to some extent redundant because the pattern provides a parsimonious description simpler and more concise than the data. Likewise, once an explanation is found for the pattern, the pattern is, to some extent, redundant because the explanation provides a parsimonious description simpler and more concise than the pattern.”
-The Genesis of Technoscientific Revolutions
Colloquially, sampling data upfront seems to be similar to some sort of dimensionality reduction. Even though their goals might be similar, both techniques are very distinct in terms of the resources they use. Dimensionality reduction is compressing a large data vector to a smaller data vector with several operations requiring different types of compute. Sampling on the other hand is just choosing some data points from the large data vector and does not involve any mathematical transforms / operations. If there were a way to get the same good latent representation from just sampling, why would we want to use compression as it requires a lot of resources to compress raw data?
Let’s look at the following examples:
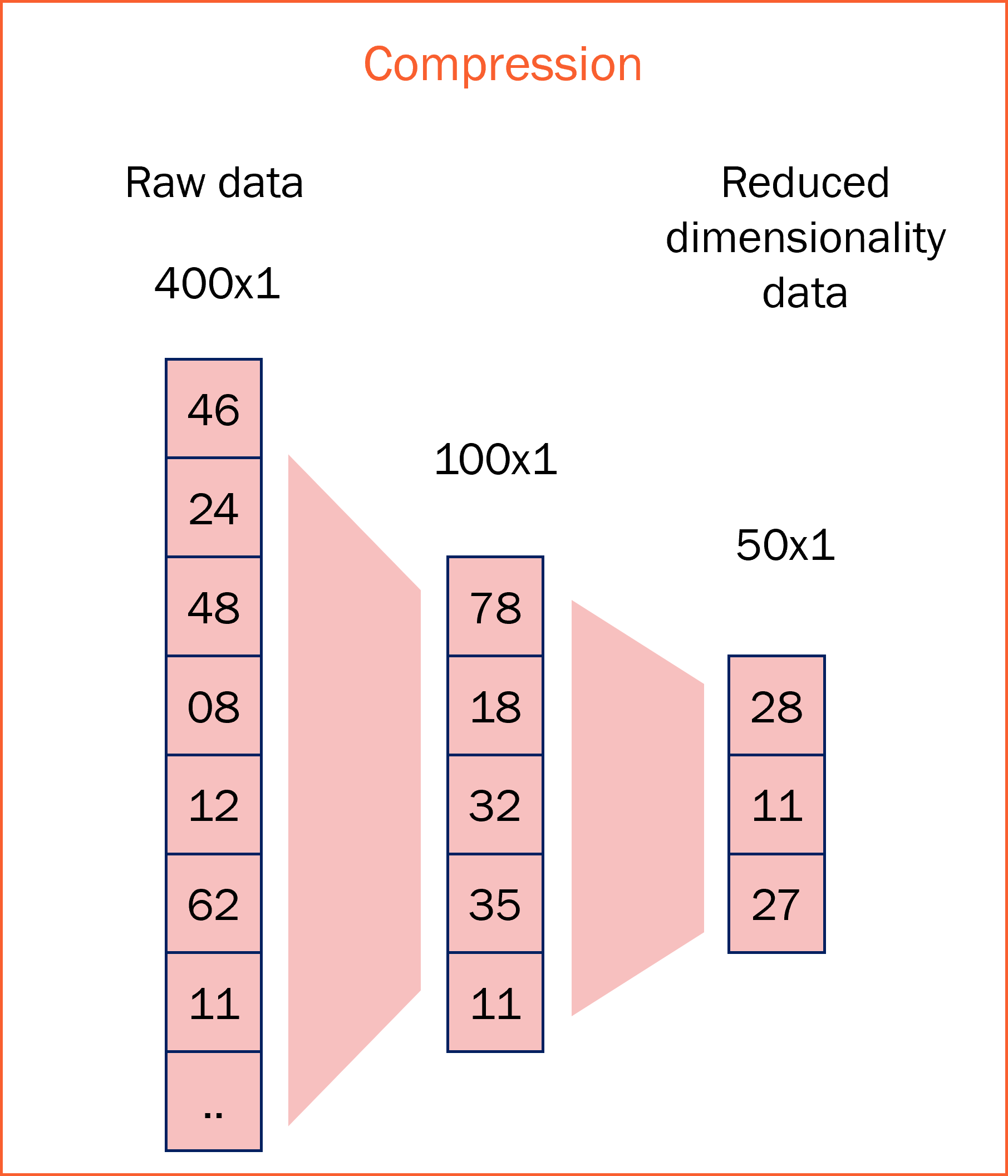
1. Compression: Compressing a data vector of size 400x1 into size 50x1. If we were to use a fully connected network for this compression, we would have to do ~400x100 + 100x50 operations, amounting to a total of ~45,000 operations. The number of operations will change depending on the architecture we use with CNNs requiring convolutions, pooling, etc.
2. Sampling: Sampling from a data vector of size 400x1 into a size of 40x1. In this case, we would begin with 40 data points, and for these to go into whatever next processing step we want to perform.
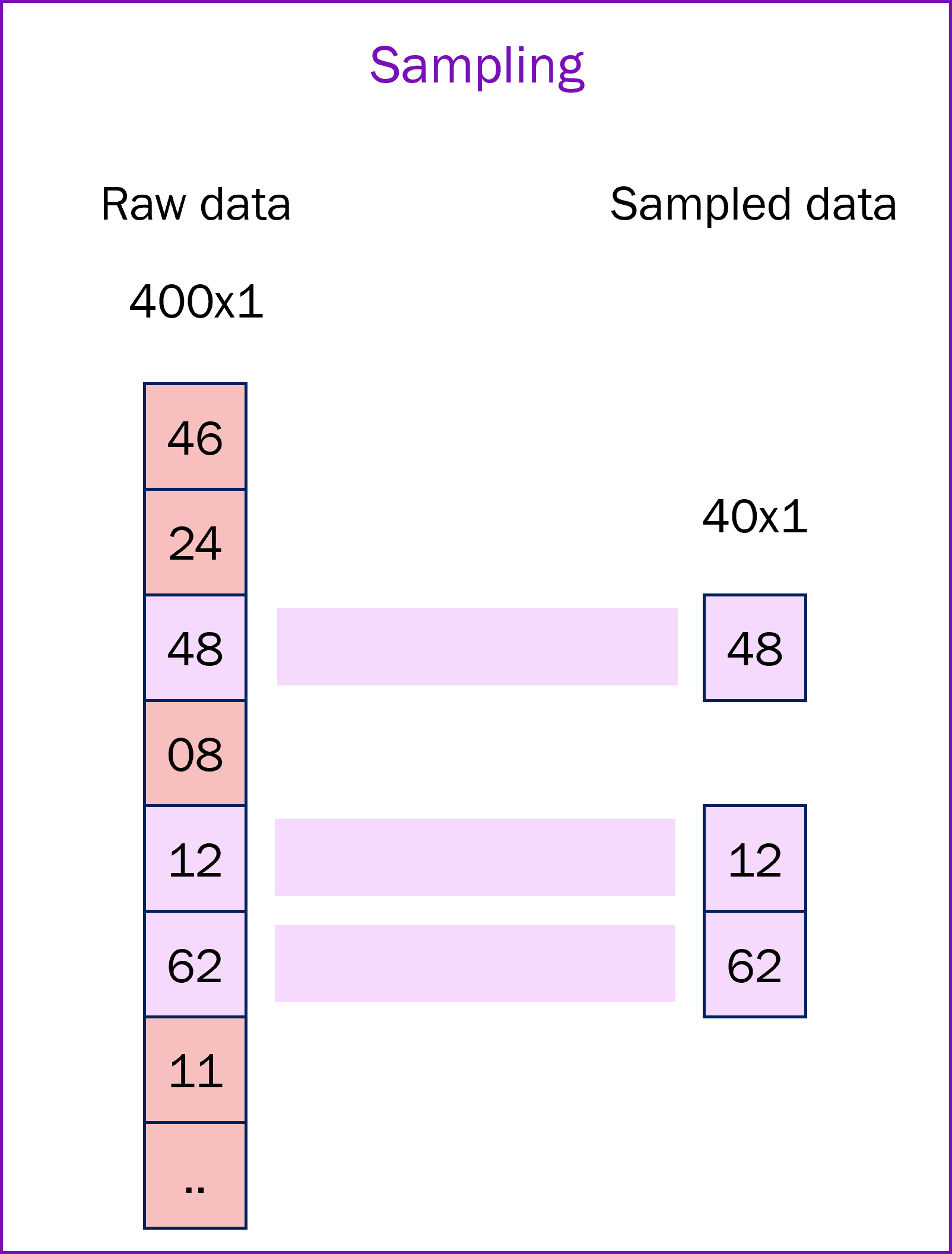
Provided there are ways to learn a good representation from this sampled data, we can get significant reduction in the amount of compute, time, power requirements to learn a good latent representation. We will be able to avoid all the processing needed to compress raw data.
Since the introduction of compressed sensing in 2006, there has been a lot of research into how to reconstruct raw data from sampled signals, with several techniques giving theoretical guarantees for reconstruction. This means that there are indeed ways to preserve information from the large data vector in a small sampled vector. The design of such sampling techniques, theory of why this works, and conditions that the large data vector must meet were all defined in the compressed sensing theory, but the scope of applicability has widened given the use of data driven techniques to address the problem of ‘how to learn a good latent representation from sampled data’.
Moreover, reducibility of raw data means it has redundancy, and that there is is no need to collect everything. Dimensionality reduction essentially means selecting data upfront should be possible. In fact, this is true even in the case of English language, which Shannon showed in his 1945 paper “A Mathematical Theory of Cryptography”, that English is 75 to 80 percent redundant. This had significant implications for cryptography.
Shannon used the following example to explain redundancy in English language:
F C T S S T R N G R T H N F C T N
To transmit the message fact is stranger than fiction one could send fewer letters. You could, in other words, compress it without subtracting any of its content.
-The Idea Factory: Bell Labs and the Great Age of American Innovation

In other words, by exploiting redundancy in different types of information, we can build techniques to identify patterns in the data using a much smaller fraction of the raw data. We do not necessarily get more information by collecting more than a certain fraction of raw data. This has important implications as we go into an age of embedding intelligence in the physical world using a variety of high-fidelity sensors.
Getting the same insights with 90% less data have significant implications for the amount of compute, power, storage, transmission, and latency required for autonomous systems like industrial machines, underwater vehicles, satellites, rovers, etc, which need to operate in resource restricted environments. This also has significant implications for the resources required for AI training and inference, with downstream impacts for energy, water, and other resources.
We are building novel AI techniques at Lightscline that are leveraging this redundancy of real world data to collect 90% less data upfront with sacrificing prediction performance. You can learn more about us here.